The artsy.net website is a Backbone.js application that talks to a server-side RESTful Grape API sitting on top of a Rails app which serves minimal HTML markup. The latter includes such things as a page title, along with links to JavaScript and stylesheet packages. A page loads, scripts run, data is fetched from the API. The result is merged into a HAMLJS template and rendered client-side.
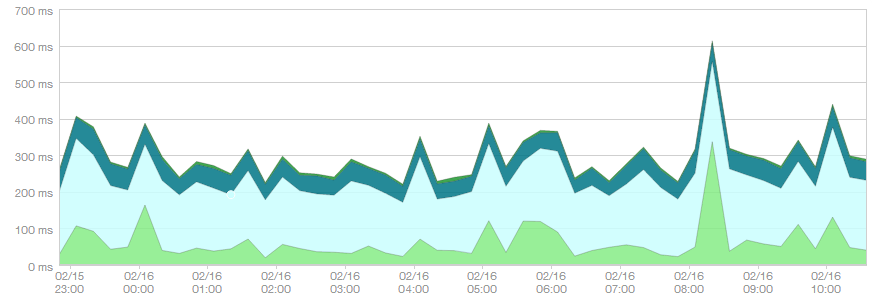
Building this kind of one-page apps allows for clean separation between the presentation and API layers. The downside is that it will slow page render times - fetching data after page load means waiting for an AJAX request to complete before displaying anything.
There’re many solutions to this problem, all involving some kind of server-side rendering. You could, for example, share views and JavaScript between client and server. This would be a major paradigm shift for a large application like ours and not something we could possibly maneuver in a short amount of time.
Without changing the entire architecture of the system, how can we bootstrap JSON data server-side and avoid the data roundtrip on every page load?