
The Artsy web team have been early adopters of node, and for the last 4 years the stable stack for the Artsy website has been predominantly been Node + CoffeeScript + Express + Backbone. In 2016 the mobile team announced that it had moved to React Native, matching the web team as using JavaScript as the tools of their trade.
Historically we have always had two separate dev teams for building Artsy.net and the corresponding iOS app, we call them (Art) Collector Web, and Collector Mobile. By the end of 2016 we decided to merge the teams. The merger has given way to a whole plethora of ideas about what contemporary JavaScript looks like and we’ve been experimenting with finding common, natural patterns between web and native.
This post tries to encapsulate what we consider to be our consolidated stack for web/native Artsy in 2017.
TLDR: TypeScript, GraphQL, React/React Native, Relay, Yarn, Jest, and Visual Studio Code.
Overview
Our web stack has been ezel.js since 2013, and continues to be a mature and well thought out technology. Since then, there has been explorations on a successor to that framework using React and GraphQL with muraljs. However, since the merger, a lot more of our focus has been on trying to find something that feels similar on both React and React Native.

TypeScript
TypeScript and Flow really moved JavaScript forwards in the last few years. They both tackle the essential problems of “how can I trust my code does what I think”, “how can I be sure of this change” and “how can I build better tools for JavaScript” in different ways.
Yes, the title of this section is TypeScript and yet I instantly include Flow. I don’t think you can, or should talk about TypeScript without understanding it’s relationship to Flow.
Both TypeScript and Flow provide a structure for applying Types to JavaScript.
Both TypeScript and Flow will infer typing metadata from untyped data.
Both TypeScript and Flow have systems for applying types to node modules.
We initially went with Flow, as Flow is a considerably easier sell to others, as it integrates inside existing JavaScript projects with less issues. Flow acts as a separate tool to a babel-based JavaScript project, whereas TypeScript is a full on replacement for that tooling.
Why bother though? JavaScript has existed for decades without type annotations, and everyone seems to have got on pretty well. One of the key features that a typing system gives you is top-notch tooling. An editor can use the type interfaces to provide auto-completion, inline documentation and inline warning/errors as you work. Type systems will help catch errors before you have even pressed save.

What works really well for typed JavaScript is that you can easily opt out of it when you need to. Then you’re back to normal “do whatever you want” JavaScript land, no problem.
We moved from Flow simply because TypeScript had better integration with Visual Studio Code (VS Code). For a few months I devoted time to improving the Flow integration in VS Code, and tried learning OCaml to help out on the Flow tool itself. In the end though, when we compared to how solid VS Code felt with TypeScript - we decided it was worth converting our projects.
Both TypeScript and Flow provide nearly every Type structure found inside Objective-C and Swift, so teaching the rest of the team how they work is easy from our native experiences.
One particularly interesting part of TypeScript that we are keeping our eyes on is this language extensibility issue, if it turns out well, we will be looking into integrating the other technologies mentioned here into TypeScript itself.

GraphQL
GraphQL is a way to handle API requests. I consider it the successor to REST when working with front-end clients. A big claim, yeah. So, what is it?
Officially GraphQL is a specification. A server can conform to the GraphQL spec, and then clients can make queries against it. Think of it a bit like how SQL is a standardized way of doing database queries across multiple databases types.
As a client, you send a “JSON-shaped query” structure, which is hierarchical and easy to read:
{
artwork(id: "kimber-berry-as-close-to-magic-as-you-can-get") {
id
additional_information
is_price_hidden
is_inquireable
}
}
This will search for a specific artwork, with the response JSON as the Artwork’s
id,additional_information,is_price_hiddenandis_inquireable.
It’s important to note here, the data being sent back is specifically what you ask for. This is not defined on the server as a short or embedded version of a model, but the specific data the client requested. When bandwidth and speed is crucial, this is the other way in which GraphQL vastly improves an app-user’s experience.
This is in stark contrast to other successors to REST APIs, the hypermedia APIs, like HAL and JSON-API - both of which are optimised for caching, and rely on “one model, one request” types of API access. E.g. a list of Artworks would actually contain a list of hrefs instead of the model data, and you have to fetch each model in a separate request.
Hypermedia APIs have a really useful space in cross-server communications, but are extremely wasteful of the most precious resource for a front-end device - bandwidth. Latency matters considerably, on mobile where bandwidth is spotty, and attention spans are short you need to do everything possible to show more than a loading spinner.
I have previously explored our usage of GraphQL from the perspective of a native developer in 2016. So I’ll leave that post to describe our implementation of a GraphQL server.
One exciting movement in the space of GraphQL is GitHub moving to GraphQL for their new APIs.
React / React Native
React is a Facebook project which offers a uni-direction Component model that can replace MVC in a front-end application. React was built out of a desire to abstract away a web page’s true view hierarchy (called the DOM) so that they could make changes to the view in memory and then React would handle finding the differences between view states.
You create a set of Components to encapsulate each part of the state of the page. React makes it easy to make components that are functional in the Functional Reactive Programming sense. They act like a function which takes some specially declared state and it is rendered into HTML.
A component optionally uses a language called JSX to visualise how each component’s child components are set up, here’s an example of a React component using JSX from Emission, our React Native library:
export default class SearchBar extends React.Component {
render() {
return (
<TouchableWithoutFeedback onPress={this.handleTap.bind(this)}>
<View style={styles.container}>
<Image style={styles.searchIcon} source={require('../../../images/SearchButton.png')}/>
<Text style={styles.text}>Search for artists and artworks...</Text>
</View>
</TouchableWithoutFeedback>
)
}
handleTap() {
Switchboard.presentModalViewController(this, '/search')
}
}
By providing a well encapsulated Component model, you can aggressively reduce the amount of redundant code you need to build an application. By not initially writing to the DOM, React can decide what has changed between user actions and that means you have to juggle significantly less state.
We can then build on React via React-Native to allow the same style of code to exist inside the mobile sphere, where typically you have had unique languages and tooling.
React Native is an implementation of React where instead of having React’s virtual DOM map to a web page’s DOM, it creates a native view hierarchy. In the case of iOS that is a UIView hierarchy, and in Android, a View hierarchy.
If you’d like to find out why the iOS team moved to React Native, check our series of posts on React Native.

Relay
Any front-end client has a lot of work to do on every page:
- Fetching all the data for a view hierarchy.
- Managing asynchronous state transitions and coordinating concurrent requests.
- Managing errors.
- Retrying failed requests.
- Updating the local cache after receiving new results/changes the server objects responses.
- Optimistically updating the UI while waiting for the server to respond to mutations.
This is typically handled in a per-page basis, for example the API details, and state management between a Gene page, and an Artist page are different. In part because they have different data-models, but also that they have different correlated data. However, they do share a lot of the common responsibilities mentioned above. In our native side, we struggled to find abstractions that would work across multiple pages. Relay fixes this, and does it in a shockingly elegant way.
Relay is a framework for building data-driven React apps which relies on a deep connection to GraphQL. You wrap your React components inside a Relay container, which handles the networking and setting the state for your component.
// This is a normal React component, taken directly from our app
// It will optionally show a description if one exists on a gene.
class Biography extends React.Component {
render() {
const gene = this.props.gene
if (!gene.description) { return null }
return (
<View>
<SerifText style={styles.blurb} numberOfLines={0}>{gene.description}</SerifText>
</View>
)
}
}
// Take the above component `Biography`, and wrap it with a Relay Container.
// Then provide what parts of a GraphQL request the `Biography` needs
export default Relay.createContainer(Biography, {
fragments: {
gene: () => Relay.QL`
fragment on Gene {
description
}
`,
}
})
// When the `Biography` component is rendered, the component is given props of
// `gene` with a `description` by the Relay container.
Relay handles this by having each component in your view hierarchy exposing the fragments of a GraphQL query. There is a pre-render stage where all of your components fragments are brought together to make a single API request. So in the case of the Gene, it may look something like:
{
gene(id: "the-fantastic") {
// could have come from the root component's fragment
id
name
// came from the above Header fragment
description
// could have come from a RelatedArtists component's fragment
trending_artists {
name
href
}
}
}
The data is first looked up inside Relay’s local cache, and then any un-cached items are requested from the network. The results of the query is then moved into the component via it’s props. Relay will only provide the specific data each component has requested. So the Header component would get nothing for this.props.gene.name. This data-masking is a great way of ensuring the connection between component and API.
I’d strongly recommend taking the dive into both the Thinking with GraphQL and then Thinking with Relay tutorials to learn more. Finally, Learn Relay and Relay for Visual Learners are great tutorials to help you get comfortable with the concepts.

Yarn
I have a lot of respect for NPM, their scale is through the roof. They built out the foundations for a massive, thriving community. They did a great job. Like a lot of the JavaScript ecosystem, their tooling allows you to get away with a lot of things. You can have the same dependency inside the app with multiple versions, or apps with a dependency tree that is different each time you run npm install.
We have multiple engineers who have worked on a dependency manager for half a decade, having indeterminate builds in JavaScript was something that worried us greatly. Luckily, there is Yarn.
Yarn is a Facebook project that replaces the NPM cli client. It’s very new, so unlike NPM it does not have to worry about backwards compatibility. It is what I’d imagine a fresh re-write of the NPM cli would look like.
Yarn is significantly faster, has a determinate process for setting up projects and uses a lockfile by default to ensure everyone using the project gets the exact same dependency tree. It uses NPM as a server, and so you get the same node modules as with the NPM cli.
Sometimes Yarn gives you pleasant surprises too, my favourite being that yarn [x] will check to see if that is a local command that you could run, saving a bunch of redundant settings.
Converting a codebase can be as simple as going into your project and running:
npm install -g yarn
yarn install
Now you have a lockfile, and are using yarn. Awesome, if you are migrating from a project with a shrink-wrap - I have a script which will generate a summary of the changes for you: script, example.

Jest
One of the things that I find particularly pleasant about the JavaScript ecosystem are their testing tools. With our React Native, we came into the ecosystem with fresh eyes, and it was pretty obvious that Jest was an exceptional testing framework. I hear historically Jest has been a bit meh, but it is without a doubt worth another look.
The watcher - The majority of your usage of Jest is with it running in watcher mode. This mode uses your git diff as a seed for what to run tests against. Jest will use that diff to define all the files that the changed code touches, and then all of the tests that cover those files.
For example, I make a change in one source file and 60 tests run from 6 different test suites. Finishing in under a second.
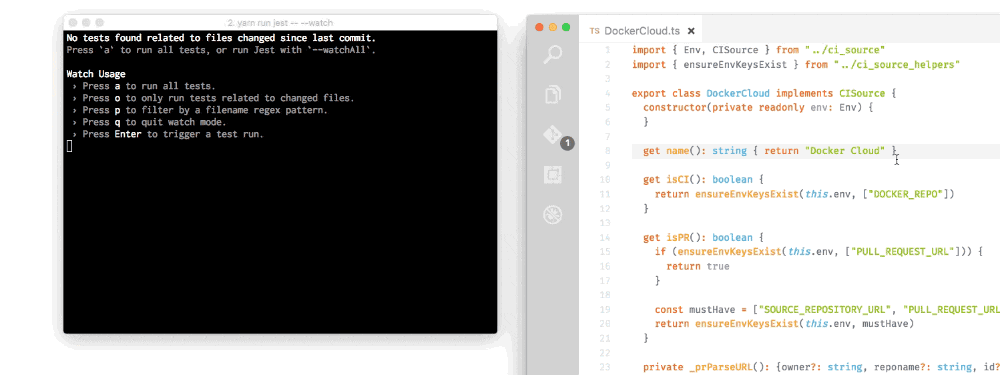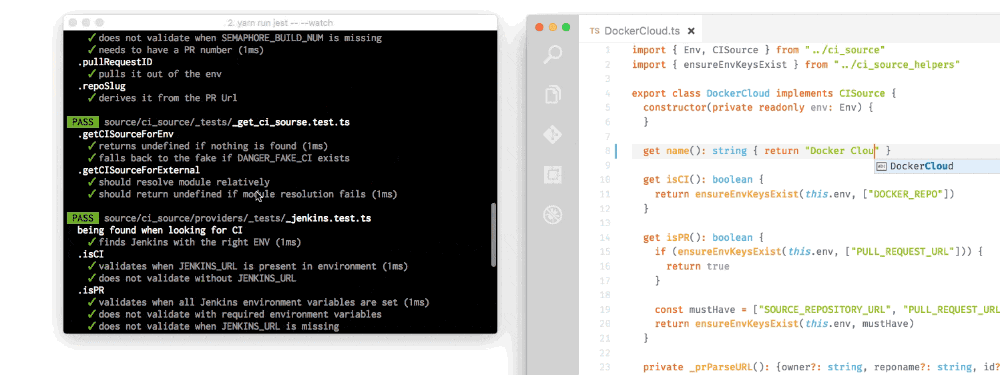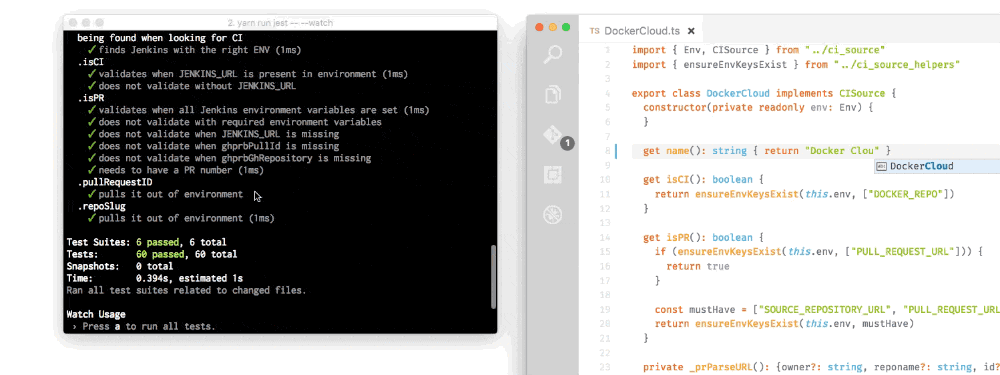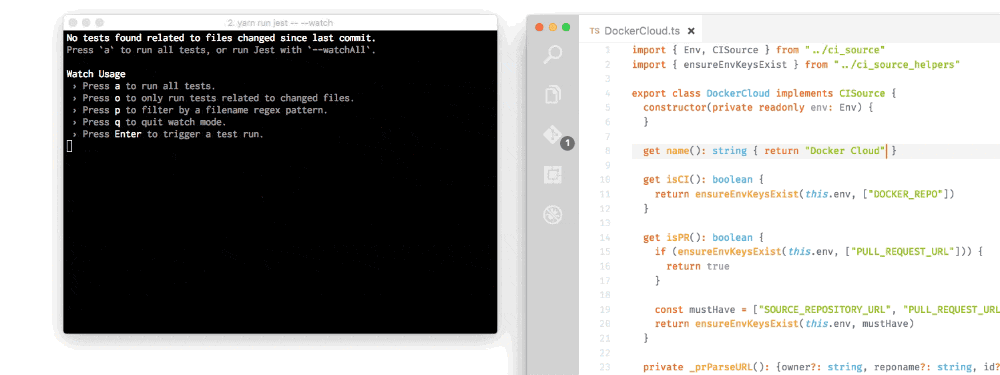
Not all tests are as important to a run, so Jest also keeps track of which tests failed last time and will run those first next time. This reduces iteration time considerably.
Fast and safe - You think the watcher is smart? Well the way Jest handle test suites is also extremely elegant. Jest keeps track of how long each test suite took to run, and then will weigh the test suites across different processes in order to speed up the overall test suite. If Jest thinks they’re all going to be really quick (like my GIF above) they will all happen in one process, as that can also be faster.
Each test suite is an entirely sandboxed node virtual machine, so you cannot have tests influencing each other.
Snapshots - Jest provides a concept called snapshots, which provides an easy way to compare JavaScript objects. One place where this really shines is with React components. For example:
it('looks like expected', () => {
const props = {
gene:{...}
}
const tree = renderer.create(
<Gene geneID={props.gene.name} medium="painting" price_range="*-100000" gene={props.gene}/>
).toJSON()
expect(tree).toMatchSnapshot()
})
Now we will get a test failure when any changes happen in the component tree. For example, if I changed the background color to blue from white. I get a fail like this:

While that example is trivial, we really want to have tests like this to ensure we understand how changes propagate throughout the app.
No config - When we first integrated Jest, we had no config. Now, to make sure that TypeScript works how we’d like, we require some setup. However, having smart defaults which works in most cases say a lot about the care and attention paid to Developer Experience from the Jest team. The documentation covers default integrations for: Babel, TypeScript and webpack. Three of the biggest modern tools for getting stuff done with node.
Comprehensive API - Snapshots, watchers, custom matchers, useful JSON output, ESLint linters, Elegant Mocking tools and natural support for async code. All in one project.
If you’re interested, there is a lot of work around automating the migration between different testing frameworks in jest-codemods - getting started has never been easier. I’d also recommend looking at wallaby.js and vscode-jest for tooling.
Visual Studio Code
Had you told me two years ago that my main editor would be a JavaScript app, I’d have bought you a beer for such a great joke.
Visual Studio Code was the app that changed my mind.
I’ve done a longer write up on the how and why we use VS Code in JavaScript projects, however here I’d like to consider the cultural aspect of the choice. It’s common practice among web technologists to all have different editors on a project, and for their editors to generally do little work for them. A lot of this culture came from the TextMate and Rails days with the infamous blog in 15 minutes video. When I was a web developer, I also did this.
When you spend a lot of time in a powerful IDE, it gets pretty hard to go back to a bare-bones editor. VS Code sits at a good (just past) half-way point between text editor and IDE. You can get a lot of the flexibility from a text editor, making it good for one off files and IDEs where you have fully spec’d out projects.
Being able to have project specific setups is where VS Code really starts to shine. One thing that is working well for us is to gradually add project settings for our apps, first we add the ability to run tests with an attached debugger by adding a launch.json:
{
"name": "Run Tests With Debugger (slower, use yarn for normal work)",
"type": "node2",
"request": "launch",
"port": 5858,
"address": "localhost",
"sourceMaps": true,
"stopOnEntry": false,
"runtimeExecutable": null,
"runtimeArgs": [
"--debug-brk",
"./node_modules/.bin/jest",
"-i"
],
"cwd": "${workspaceRoot}"
}
With this we can showcase how easy it is to use an inline debugger with source-maps, when working with tricky test logic. No more console.log. That’s usually a great way to start moving everyone to a consistent environment. Then we add recommended extensions to the project.
Trying to set a consistent development environment might sound a bit corporate for a ~25 person dev team, but one chief advantage is that you can feel comfortable taking time at work to improve your tooling knowing it will improve the tooling of everyone else on your team.
I’ve been exploring a consolidated Artsy VS Code extension to handle extension dependencies and small tasks, but it’s still early days. It’s awesome that I can even think at that level of abstraction though.
End
None of these technologies are under a year old, all of them have adoption by substantial amount of companies. Nothing feels either controversial or novel. This is great. It feels like a lot of the interesting work for us so far has been around improving the spaces between the projects: Finding improvements for generating types from GraphQL or Relay, adding editor support to jest, adding Danger to our dependencies and improving our tooling for vscode. The front-end is still a pretty small dev team, so we want to do high impact, small projects that can make our tools drastically better.
React, React-Native, Jest, Yarn are all big Facebook projects. In the iOS world, there is a sense of wariness around building an app so heavily around Facebook tech, based on three20 - which I think is a bit unfair. From my perspective, determining whether you should have something as a dependency should be nuanced, but at a minimum you should feel like you can contribute bug fixes and ideally you should be able to maintain the project if it needs it. With Facebook projects, they’ve shown to be really open to PRs and discussion, and our work in them makes us feel comfortable to maintain a fork if needed.
We’re still exploring the space where we can share code between web and mobile. I’d like to hope within a few months we can write up how that is going on. For now, if you’re interested in prototypes, we’ve been moving our React Native components to the web inside Relational Theory and Systems Theory tries bringing new ideas from Relational Theory back to React Native.
I have grown to love working with typed JavaScript to ensure soundness, with React and Relay to drastically reduce the amount of code we need to write and to provide awesome root abstractions to build on. Mix that with a hackable editor with substantial language support and it feels like almost exclusively writing business domain logic.