Artsy has now grown past 100 team members and our Engineering organization is now 20 strong. For a brief overview of what the company has accomplished in the last two years, check out our 2013 and 2014 reviews.
This is a good opportunity to describe our updated technology stack. Last time we did this was when Artsy launched publicly in 2012.

Three years ago Artsy was a classic Ruby-on-Rails monolith with a handful of adjacent processes and tools. We’ve since broken it up into many independent services, and continue to heavily be a Ruby and JavaScript shop, using Rails where appropriate, with native code on mobile devices and some JVM-based experiments in micro-services.
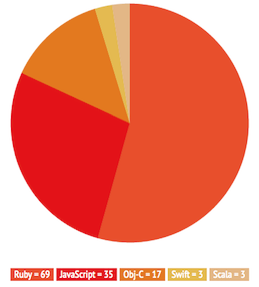
What you see today when you go to www.artsy.net is a website built with Ezel.js, which is a boilerplate for Backbone projects running on Node and using Express and Browserify. The CoffeeScript code is open-source. The mobile version of www.artsy.net is m.artsy.net and is built on the same technology. Both run on Heroku and use Redis for caching. Assets, including artwork images, are served from Amazon S3 via the CloudFront CDN.
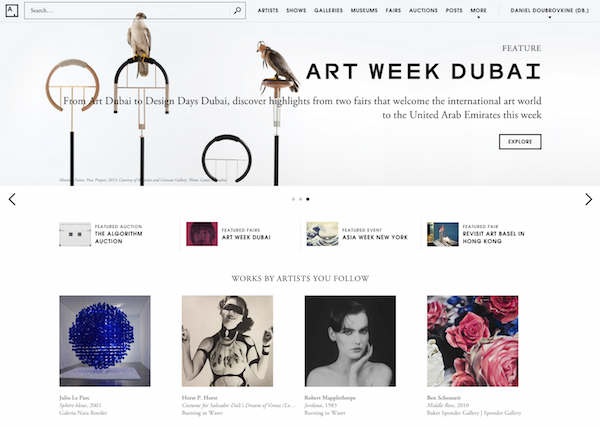
These web applications talk to a private Ruby API built with Grape, that serves JSON. We also have a more modern and better designed public HAL+JSON API. For historical reasons, both are hosted side-by-side on top of a big Rails app that used to be our original monolith. The API service runs on AWS OpsWorks and retrieves data from several MongoDB databases hosted with Compose. It also uses Apache Solr, Elastic Search and Google Custom Search. The API service also heavily relies on Memcached.
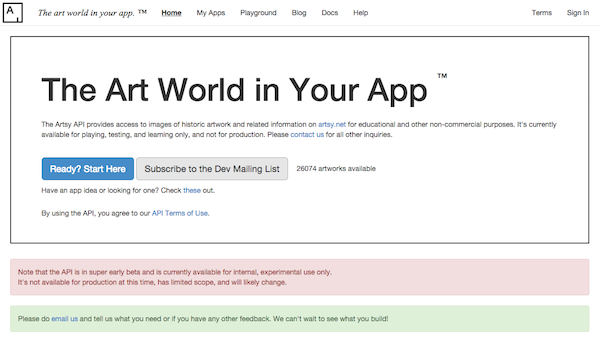
Our partners upload artworks, artists and other metadata via a home-grown content-management system built entirely from scratch in 2014 on Ruby-on-Rails. This was a deliberate “boring” choice that continues to serve us very well. We have adopted a common model for admin-type apps with a shared component library and a reusable UI, all implemented as Rails engines. Using these components we are able to quickly and easily compose beautiful and useful applications - we have built dedicated systems to manage fairs and auctions. We standardized on related services as well - for example, our customers interact with us via Intercom. We’re also experimenting with some new technologies in our internal apps, notably React.
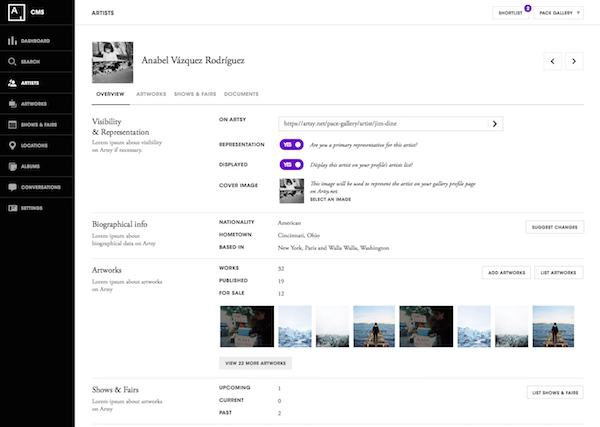
Our family of mobile applications includes Artsy for iOS, which is a hybrid app written in Objective-C, and a bidding kiosk, written in Swift. Both are open-source here and here.
A lot of data, including the artwork similarity graph that powers The Art Genome Project, is processed offline by a generic job engine, written in Ruby or by Amazon Elastic MapReduce. We take data snapshots from MongoDB, run jobs on the data and export data back to the database. Other recently rewritten services include image processing, which creates thumbnails, image tiles for deep zoom and watermarks high quality JPEGs. Several new applications use PostgreSQL.
Various front-ends pipe data to Snowplow and Segment, which forwards events to Keen, Google Analytics, MixPanel and ChartBeat. Some data is warehoused in AWS Redshift and PostgreSQL and may be analyzed offline using R or iPython Notebooks. We also have a Statsd and Graphite system for tracking high volume, low-level counters. Finally, it’s also fairly common to find a non-Engineer at Artsy in a read-only Rails console or in Redshift directly querying data.
We send millions of e-mails via SendGrid and Mandrill and use MailChimp for manual campaigns.
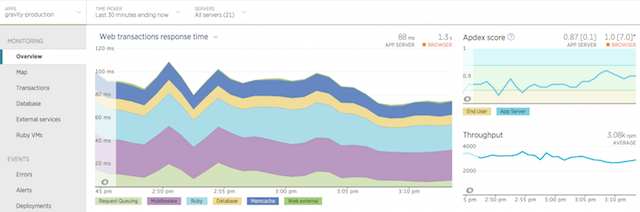
Smaller systems usually start on Heroku and larger processes that perform heavier workloads usually end up on AWS OpsWorks. Our systems are monitored by a combination of New Relic and Pingdom. All of this is built, tested and continuously deployed with Jenkins, Semaphore, and Travis-CI.
In terms of Engineering workflow we live in Github and Trello. We tend to have a workflow similar to open-source projects with individuals owning components and services and the entire team contributing to them.
In 2015 we intend to complete our transformation into small independent services built with 10x growth in mind. We can then focus on maturing the Artsy platform both vertically and horizontally and enabling many new directions for our thriving businesses.
We hope you find this useful and will be happy to describe any detailed aspect of our system on this blog. We’re always hiring, please e-mail jobs@artsy.net if you want to work with us. Finally, we welcome any questions here and look forward to answering them below!
Comments