OpsWorks is a new service from Amazon that promises to provide high-level tools to manage your EC2-based deployment. From the announcement:
AWS OpsWorks features an integrated management experience for the entire application lifecycle including resource provisioning, configuration management, application deployment, monitoring, and access control. It will work with applications of any level of complexity and is independent of any particular architectural pattern.
After scratching our heads about exactly what that meant, we tried it anyway. If you’ve been straining at the limits of your Platform as a Service (PaaS) provider, or just wishing for more automation for your EC2 deployment, you may want to try it out too.
Artsy has been experimenting with OpsWorks for a few months now and recently adopted it for the production artsy.net site. We’re excited to share what we’ve learned in the process.
Why OpsWorks?
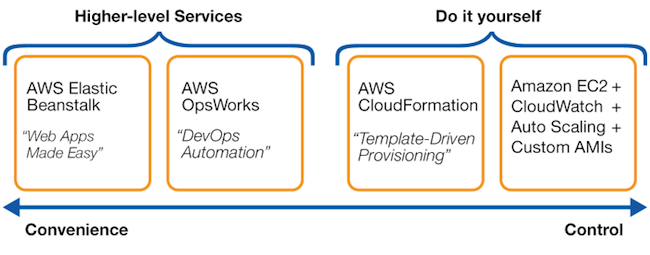
If you’ve worked with the confusing array of AWS services in the past, you’re already wondering how OpsWorks fits in. Amazon’s own Elastic Beanstalk or PaaS providers such as Heroku typically focus on making your application as simple as possible to deploy. You don’t have to worry about the underlying hardware or virtual resources; the platform manages that transparently. Dependencies (such as a data-store, cache, or email server) often take the form of external services.
But this simplicity comes at a cost. Your application’s architecture is constrained to a few common patterns. Your functionality may be limited by the system packages available in the standardized environment, or your performance may be limited by the available resources. OpsWorks offers more flexibility and control, allowing you to customize the types of servers you employ and the layers or services that make up your application. It’s a lower-level tool than those PaaS providers.
Conversely, OpsWorks offers higher-level control than CloudFormation or than managing EC2 instances and related services directly. By focusing on the most commonly used AWS services, instance types, and architectures, it can provide greater automation and more robust tools for configuration, authorization, scaling, and monitoring. Amazon CTO Werner Vogels rendered it thus:
Historically, Artsy delegated dev-ops concerns to Heroku. They worried about infrastructure, freeing us to focus on our application’s higher-level goals. Increasingly though, we were forced to work around limitations of the platform’s performance, architecture, and customizability. (We even blogged about it here, here, here, here, and here.) Rather than continue to work against the platform, we turned to OpsWorks for greater flexibility while keeping administrative burden low.
OpsWorks Overview
OpsWorks comes with a new vocabulary. Let’s look at the major concepts:
- A Stack is the highest-level container. It groups custom configuration and houses one or more applications. To manage a simple to-do list site, you’d create a todo stack, although you might choose to have separate todo-production and todo-staging stacks.
- Each stack has one or more Layers. Think of these as definitions for different server roles. A simple static web site might have a single Nginx layer. A typical web application might instead have a load-balancer layer, a Rails layer, and a MySQL layer. OpsWorks defines plenty of built-in layers (for Rails, HAProxy, PHP, Node, Memcached, MySQL, etc.), but you can also define your own.
- Applications are your code, sourced from a git or subversion repository, an S3 bucket, or even an external web site. A typical Rails site might have a single application defined, but you can define multiple applications if you’d like to configure, scale, and monitor them together.
- Finally, we define Instances and assign each to one or more layers. These are the EC2 servers themselves. You can start instances manually, or configure them to start and stop on a schedule or in response to load patterns.
Configuring your stack
If your app employs a common architecture, you can probably use the OpsWorks dashboard to define layers, add a few instances, link your git repo and be up and running. Examples:
- A static web site hosted on Nginx
- A single-server PHP app
- A Rails app with an HAProxy load-balancer, unicorn app servers, and MySQL database
- A Node.js app using Elastic Load Balancer and a Memcached cache
You can find detailed walk-throughs of a few such common use cases in the OpsWorks docs.
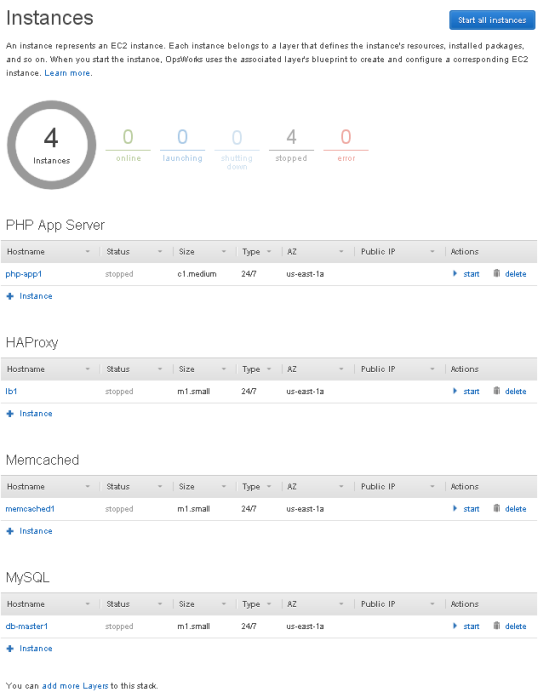
If the built-in layers don’t quite satisfy your needs, there are several facilities for customization. But first, it’s useful to understand how OpsWorks manages your instances.
Chef cookbooks
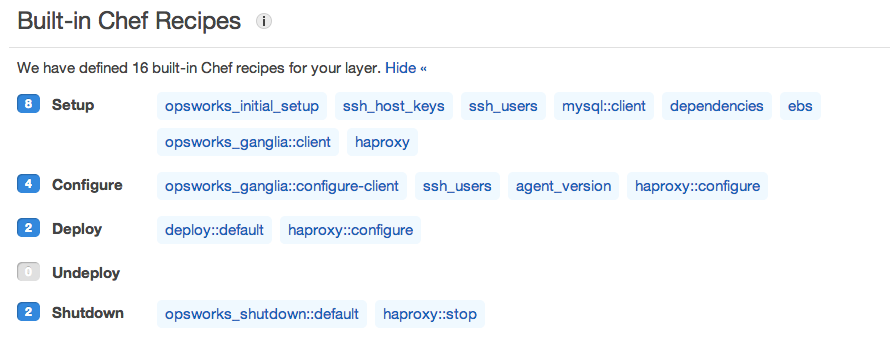
OpsWorks uses Chef to configure EC2 instances. If you’re unfamiliar, Chef is a popular tool for making server configuration more automated and repeatable—like code. The Chef “recipes” that configure each layer are open-source and available in the opsworks-cookbooks github repo. (Cookbooks contain one or more “recipes”—get it?) There, you can see precisely what commands are run in response to server lifecycle events (i.e., as servers are started, configured, deployed to, and stopped). These recipes write out configuration files, restart services, authorize users for SSH access, ensure logs are rotated, etc.—everything typical deployments might need.
For example, the recipes that set up an HAProxy instance look like this:
Overriding configuration “attributes”
Chef cookbooks accept parameters in the form of “node attributes.” The default attributes will serve you well in most cases. To override them, edit the stack’s custom Chef JSON. For example, to configure Unicorn to run 8 workers instead of 16 and Memcached to bind to port 11212 instead of 11211, you’d enter the following for your stack’s custom JSON:
{kind=link}
Custom cookbooks
If setting node attributes isn’t sufficient, you can go further and override the files written out by your layer’s recipes. Simply toggle the Use custom Chef cookbooks option in your stack settings and provide a link to a git, subversion, S3, or HTTP location for your custom cookbooks.
Your custom cookbooks bundle can also contain original or borrowed recipes that perform any other custom configuration. Tell OpsWorks when to run your recipes by associating them with the desired events in your layer settings. For example, we use custom recipes at our Rails layer’s setup stage to perform additional Nginx configuration, install a JavaScript runtime, and send logs to Papertrail.
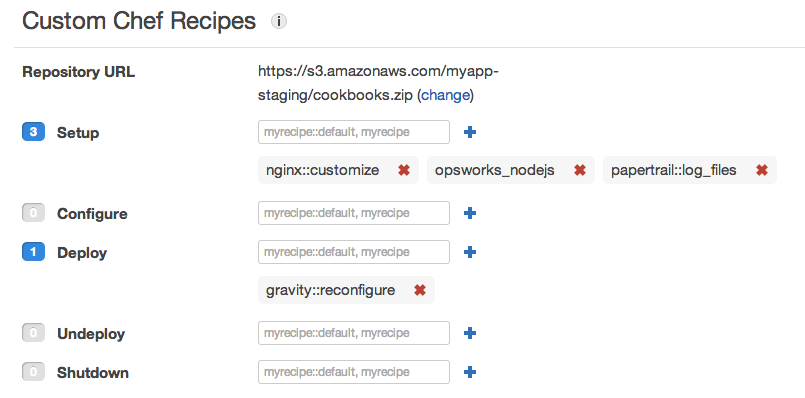
OpsWorks shares details about the entire stack with recipes via node attributes, allowing custom recipes to connect to other instances as required.
Custom layers
If the built-in layers don’t satisfy your needs even after customization, you can create custom layers. The base OpsWorks configuration is provided (for SSH authorization, monitoring, etc.) and your custom recipes do the rest. For example, we created a custom layer to process background jobs:
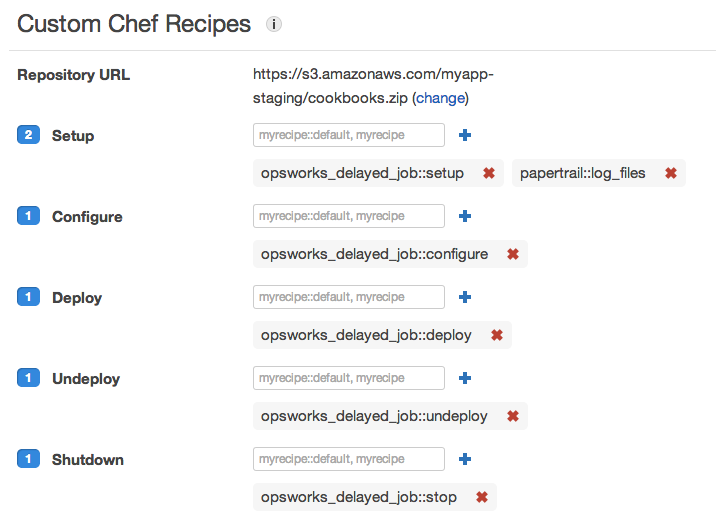
Down the road, we might introduce additional layers for Redis, Solr, or MongoDB. (Even better, AWS may introduce built-in support for these.)
Performance
OpsWorks makes most EC2 instance types available, so we can choose an appropriate balance of CPU power, memory, disk space, network performance, and architecture for each instance. This can be a huge boon to the performance of resource-constrained applications. It probably still pales in comparison to running directly on physical hardware, but this benefit alone could make OpsWorks a worthwhile choice over providers of “standard” computing resources.
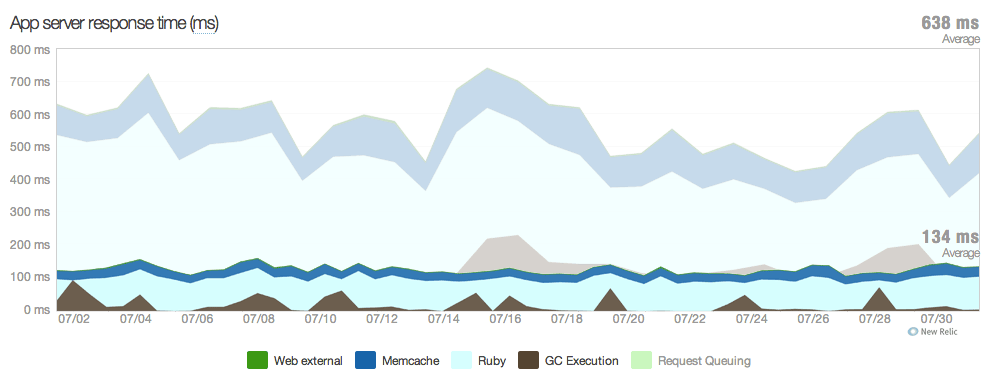
While not a rigorous comparison, the experience of one of our particularly memory-constrained applications illustrates this. The application’s responses took an average of 638 milliseconds when running on Heroku’s “2x” (1 GB) dynos. The same application responded in only 134 milliseconds on OpsWorks-managed m1.large instances (with 7.5 GB). That’s a ~80% (5x) improvement!
Troubleshooting
That’s all well and good, but what about when things aren’t working?
We’ve experienced our fair share of failures with both OpsWorks and Heroku. PaaS providers like Heroku offer a pleasant abstraction, but in doing so reduce our visibility into the systems running our application. (Want to know why a dyno seems to be performing poorly? Good luck diagnosing resource contention, disk space problems, or network latency.) Instead, we’re reduced to repeatedly issuing restart commands.
In contrast, I can easily SSH into an OpsWorks instance and notice that a runaway process has pegged the CPU or that a chatty log has filled the disk. (Of course, the additional control afforded by OpsWorks increases the chance that I’ve caused the problem myself.)
Which do we prefer? We’d probably be safer with Heroku’s experts in charge, but I’ll happily accept light sysadmin duties in exchange for the flexibility OpsWorks affords. And by sticking with the OpsWorks default recipes as much as possible, we benefit from the platform’s combined experience.
Scaling and recovery
Scalability and recovery are critical, so how does OpsWorks compare to full-featured PaaS providers? Pretty well, actually.
OpsWorks instances can be launched in multiple AWS availability zones for greater redundancy. And if an instance fails for any reason, OpsWorks will stop it and start a new one in its place.
Especially useful is the automatic scaling, which can be time-based or load-based. This nicely matches the horizontal scaling needs of our app: we’ve chosen to run additional Rails app servers during peak business hours, and additional background workers when load on existing servers exceeds a certain threshold.
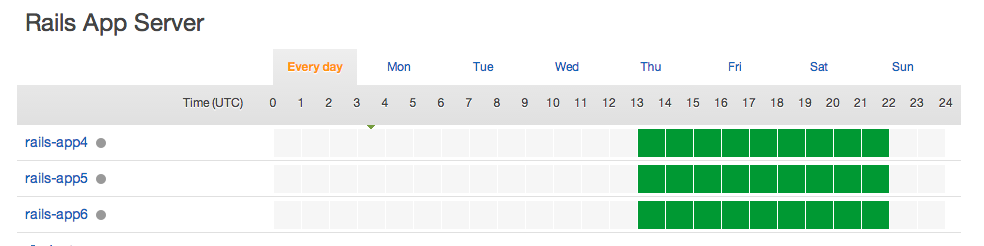
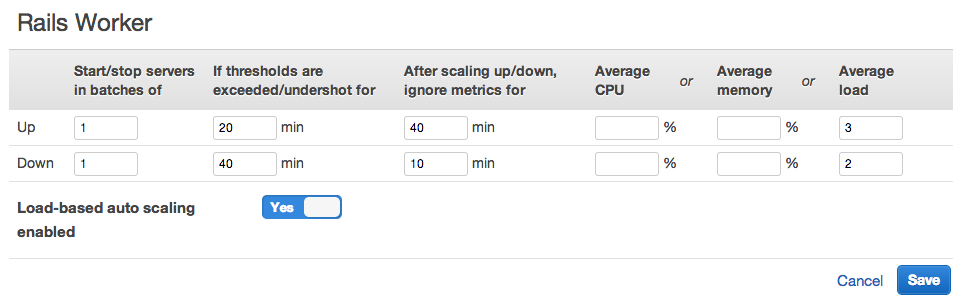
When background workers are busy, new instances spin up automatically to tackle the growing queue. That is dev-ops gold.
Monitoring
OpsWorks provides a monitoring view of each stack, with CPU, memory, load, and process statistics aggregated by layer. You can drill down to individual instances and review periods anywhere from 1 hour to 2 weeks long.
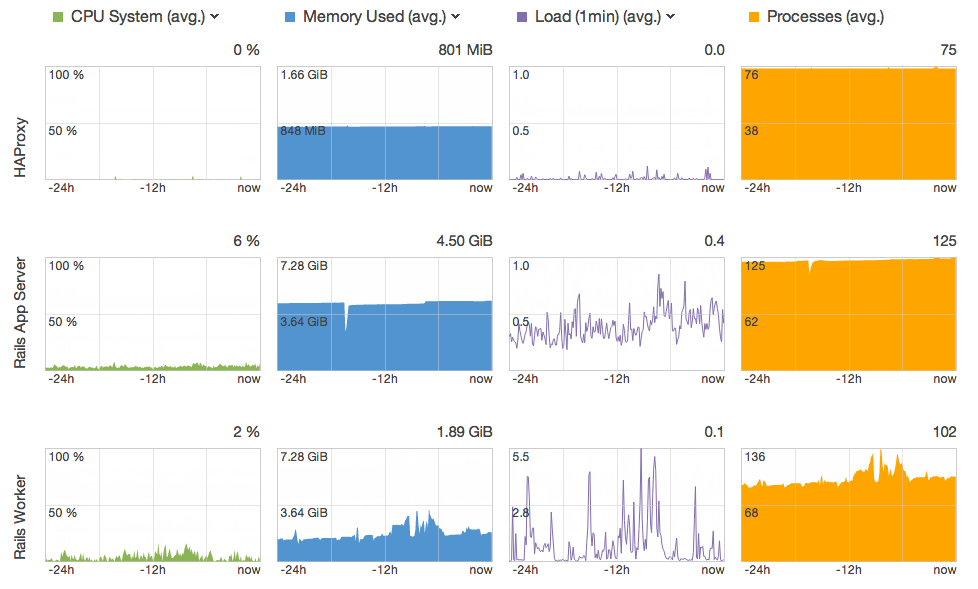
We haven’t tried it, but OpsWorks also offers a built-in Ganglia layer that automatically collects metrics from each of your stack’s instances.
Conveniently, AWS also sends these metrics to its own CloudWatch monitoring service, where you can configure custom alerts.
Integration with other AWS services
You might be noticing a theme here: OpsWorks leverages AWS’s other tools and services quite a bit.
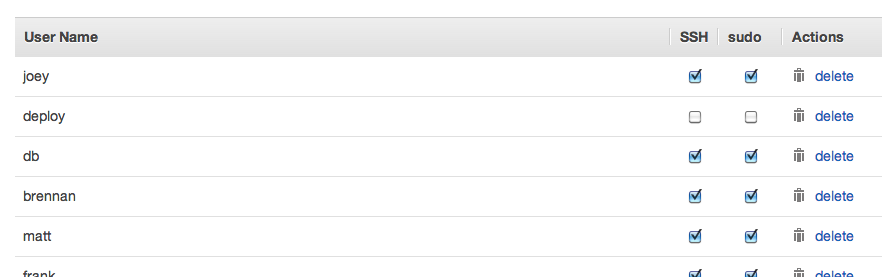
Identity and Access Management (IAM) allows you to define individual user accounts within an umbrella account for your organization. These users can be authorized for varying levels of access to your OpsWorks stacks. From the Permissions view of each stack, you can then grant them SSH and sudo rights on an individual basis.
Other tools such as the EC2 Dashboard and AWS API work as you’d hope, with all of the usual functions being applicable to your OpsWorks-managed instances and other services like elastic IPs and EBS volumes.
Cost
Pricing is simple and enticing. There’s no charge for using OpsWorks; you pay only for your underlying usage of other AWS resources like EC2 instances, S3 storage, bandwidth, elastic IPs, etc. If you’ve purchased reserved instances, those savings will apply as usual.
Unfortunately, OpsWorks doesn’t yet support spot instances (but I imagine that’s in the works).
Roadmap
In the few months since its launch, OpsWorks has added support for ELB, monitoring, custom AMIs, and more recent versions of Chef and Ruby. There’s also an active discussion forum where developers and Amazon employees circulate issues and request features. It’s a relatively new service and can occasionally be rough around the edges, but–knowing AWS–we expect the current pace of enhancements to continue.
We’ve already launched one major app on OpsWorks and will be looking for more opportunities as it gains a following and grows in sophistication.
Look for a follow-up post where we document our experience transitioning an app from Heroku to OpsWorks!
Comments