When the mobile team at Artsy considered [moving to React Native][iosrn] back in 2016, one of the most compelling cases for making that jump was Relay. This, it seems, is a dependency that is rarely used in the JS community and we often find ourselves re-explaining this decision to new engineers during onboarding, and to the public at large.
Which makes this a perfect blog post topic, so let’s have a deep dive into what makes Relay compelling for Artsy’s engineering team.
What problem does Relay solve?
Relay is an API client for GraphQL, it comes in two parts: a compiler and a set of front-end components. Relay aims to provide a really tight binding between your GraphQL API and your view hierarchy. When you build data-driven apps, Relay removes a whole suite of non-business logic from your application.
Relay handles:
- Data binding (API → props)
- Cache management (invalidation, re-render live components with data updates, etc)
- Consistent abstractions for bi-directional pagination
- Multiple query consolidation (e.g. consolidate all API requests to one request)
- UI best practices baked in (e.g. optimistic response rendering)
- Declarative data mutation (describe how data should change, instead of doing it)
- Compile-time query generation (removing runtime overhead and allowing you to persist queries)
By taking the responsibilities of the grunt work for most complex apps and moving it into Relay you get Facebook-scale best-practices and can build on top of that.
How does it work?
You write a set of Relay components, you always start with a [QueryRenderer][query] and a tree of either
[FragmentContainer][frag], [RefetchContainer][re] or [PaginationContainer][pag]s. You mostly use
FragmentContainers, so I’ll focus on that here.
A FragmentContainer is based on a [GraphQL fragment][gql-frag]. If you’ve never used a fragment, they are an
abstraction that lets you declare shared field-selections on a specific GraphQL type to reduce duplication in your
queries. For example:
query GetPopularArtistAndFeaturedArtist {
featuredArtist {
id
name
bio
}
popularArtist {
id
name
bio
}
}
To move this query to use fragments:
query GetPopularArtistAndFeaturedArtist {
featuredArtist {
...ArtistMetadata
}
popularArtist {
...ArtistMetadata
}
}
fragment ArtistMetadata on Artist {
id
name
bio
}
It’s a tiny bit longer, but you have a guarantee that the data is consistent across both artists. Now that you have
a rough idea of what a GraphQL fragment is, let’s look at what a FragmentContainer looks like. Here’s a
simplified [profile page] from the Artsy iOS app:
import React from "react"
import { createFragmentContainer, graphql } from "react-relay"
import { MyProfile_me } from "__generated__/MyProfile_me.graphql"
interface Props extends ViewProperties {
me: MyProfile_me
}
export class MyProfile extends React.Component<Props> {
render() {
return (
<View>
<Header>
<ProfilePhoto initials={this.props.me.initials} image={this.props.me.image} />
<Subheading>{this.props.me.name}</Subheading>
</Header>
<ButtonSection>
<ProfileButton
section="Selling"
description="Sell works from your collection"
onPress={startSubmission}
/>
<ProfileButton
section="Account Details"
description="Email, password reset, profile"
onPress={goToUserSettings}
/>
</ButtonSection>
</View>
)
}
}
export default createFragmentContainer(MyProfile, {
me: graphql`
fragment MyProfile_me on Me {
name
image
initials
}
`
})
There are three moving parts:
- The TypeScript interface
MyProfile_me, generated by the compiler, which ensures we can only use fields that were selected in the fragment - The
MyProfilecomponent, which is a vanilla React component - The exported
createFragmentContainerwhich returns a higher-order component that wrapsMyProfileand ties it to a fragment on aMetype in GraphQL
Isolation
The React component MyProfile will be passed in props that directly tie to the fragment that was requested. In
Relay terms, this is called [data masking][masking] and it is one of the first hurdles for someone new to Relay to
[grok][]. In REST clients, and GraphQL API clients like Apollo Client, you make a request and that request is
passed through the React tree. E.g.

This means most components know more about the request than it probably needs, as it may be needed to pass on to the component’s children. This can lead to over-fetching, or even worse, not knowing if you can delete or refactor a component.
Data masking solves this by hiding data that the component didn’t request. I’ve still yet to find the right visual abstraction, but I feel this just about pays for itself.
You let Relay be responsible for consolidating all your fragments into a query via the QueryRenderer, causing the
network request, and your response data to be passed your through your component hierarchy. This means Relay
powered components can be safely changed and drastically reduces the chance for unintended consequences elsewhere.
This isolation gives Artsy engineers the safety to work on projects with tens of contributors which regularly change over time. Providing a guarantee that you can safely work in isolated parts of the codebase without accruing technical debt.
Relay’s container components mean that the components we create are nearly all focused only on the data-driven aspects of rendering a subset of that GraphQL response into views. It’s very powerful.
Co-location
Relay helped us move to one file representing everything a component needed. Effectively a single file now handles the styles, the actual view content hierarchy, and the exact parts of the API it needs to render itself.
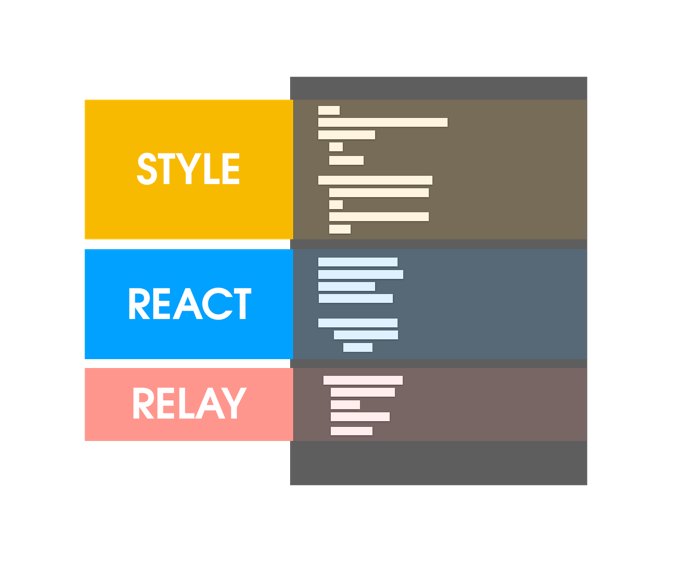
In roughly that proportion too, though our most modern code uses the Artsy design system [Palette][palette] which drastically reduces the need for style in our components.
Co-location’s biggest selling point is reducing cognitive load, having everything you need in one place makes it easier to understand how a component works. This makes code review simpler, and lowers the barrier to understanding the entire systems at scale.
Community
When we adopted Relay, there was no competition - we’d have just used the fetch API. Over time, [the Apollo
team][apollo] came up and really put a considerable amount of effort into lowering the barriers to entry, and
making it feasible to build complex apps easily.
As we hired a set of new engineers, the “Apollo vs Relay” debate came up. Interested in whether we would still start with Relay today, we ran an audit last year of what it would take to re-create a lot of the infrastructure we love in Relay atop of the (much more popular) Apollo GraphQL eco-system and saw it was reasonably feasible but would require a considerable amount of work across many different plugins and tools. With Relay that’s all packaged into one tool, works consistently and has been proven with Facebook having tens of thousands of Relay components in production.
It’s worth highlighting the core difference in community engagement for Apollo vs Relay. Engineers working on Apollo have great incentives to do user support, and improve the tools for the community - that’s their businesses value. Relay on the other hand is used in many places at Facebook, and the engineers on the team support internal issues first. IMO, this is reasonable: Relay is an opinionated batteries-included framework for building user interfaces, and ensuring it works with the baffling amount of JavaScript at Facebook is more or less all the team has time for.
That leaves space for the OSS community to own their own problems. Notably there’s been quite a lot of work going on in the community-managed [relay-tools][relay-tools] GitHub organization.
Scale Safety
Relay puts a lot of emphasis on ahead-of-time safety. The Relay compiler validates your queries against your GraphQL schema, it emits Flow types for your fragment’s field selections–which we’ve extended to emit TypeScript types instead, and there are strict naming systems enforced by the compiler. All of these help guide engineers to build scalable codebases.
How this works in practice is that whenever you need to change the data a component requires, you edit the fragment, the Relay compiler verifies your query, if successful then your TypeScript types are updated and you can use the new property in your React component above. See below for a [quick video][vid] showing the Relay compiler in action:
</article>