How important is a single artwork within the artist’s body of work? At Artsy we try to answer this question by extracting and scoring a set of features across roughly one million artworks. We call it an iconicity score and we calculate that in Apache Spark for the entire dataset in under 5 minutes.
Extracting Features
First, we retrieve artwork features (eg. artwork size or number of users that liked the work), artist features (eg. number of users following an artist), the origin of the work (eg. the work is in a museum) and art genome data (eg. an art historically important sculpture) from HDFS using Hive. Here’s a subset of the query.
case class Artwork(
val id: Int,
val partnerType: String,
val artistFollowsCount: Long = 0
) = {
def isMuseumWork: Boolean = {
partnerType == "museum"
}
}
def getArtworks(hc: HiveContext): RDD[Artwork] = {
hc.sql(
s"""
|SELECT
| artwork.id,
| partner.type,
| artist_follows_count,
|FROM
| db.artworks AS artwork
|LEFT JOIN db.partners partner
| ON partner.id = partner_id
|LEFT JOIN db.artists artist
| ON artist.id = artwork.artist_id
|LEFT JOIN (
| SELECT follow_artists.artist_id, COUNT(*) AS artist_follows_count FROM db.follow_artists GROUP BY follow_artists.artist_id
|) artist_follows_count ON artist_follows_count.artist_id = artwork.artist_id
""".stripMargin
).rdd.map {
row =>
Artwork(
id = row.getString(0)
partnerType = row.getString(1)
artistFollowsCount = row.getLong(2)
)
}
}
Some features are binary and others require minor transforms. For example, the fact that the work belongs to a museum scores 1, and otherwise scores a 0.
case class Features(
val artworkId: Int,
val artistFollowsCount: Long = 0,
val isMuseumWork: Int = 0
)
def extractFeatures(artworks: RDD[Artwork]): RDD[Features] = {
artworks.map { artwork =>
Features(
artworkId = artwork.id,
artistFollowsCount = artwork.artistFollowsCount,
isMuseumWork = if (artwork.isMuseumWork) 1 else 0
)
}
}
Features are packed in a vector to become usable by the built-in Spark functions.
case class Features(
...
) = {
def vector: Vector = {
Vectors.dense(
numArtistFollowers.toDouble,
isMuseumWork.toDouble
)
}
}
Normalizing and Weighing Features
Since having 10,000 artist followers doesn’t make a work 10,000 times more important than the fact that it belongs to a museum, we must normalize them for unit variance across the entire data set. This is also a good time to weigh some features more than others according to our understanding of the art world.
import org.apache.spark.mllib.feature._
import org.apache.spark.mllib.linalg._
def normalize(features: RDD[Features]): RDD[(Int, Vector)] = {
val scaler = new StandardScaler().fit(features.map(f => f.vector))
val weightAdjuster = new ElementwiseProduct(Vectors.dense(
0.5, // number of users following an artist is a popularity contest
2.0 // having a work in a museum is a big deal
))
features.map { f =>
(
f.artworkId,
weightAdjuster.transform(
scaler.transform(f.vector)
)
)
}
}
Scoring Artworks
The score is just the sum of the normalized and weighted features.
def score(normalizedFeatures: RDD[(Int, Vector)]): RDD[(Int, Double)] = {
normalizedFeatures.map {
f => (f._1, f._2.toArray.sum)
}
}
Storing Data
We write this data in JSON format to S3, then load it in a system that serves the Artsy API.
Conclusion
In our dataset this creates a nice distribution. Here’s an example of iconicity across works by the street artist Banksy.
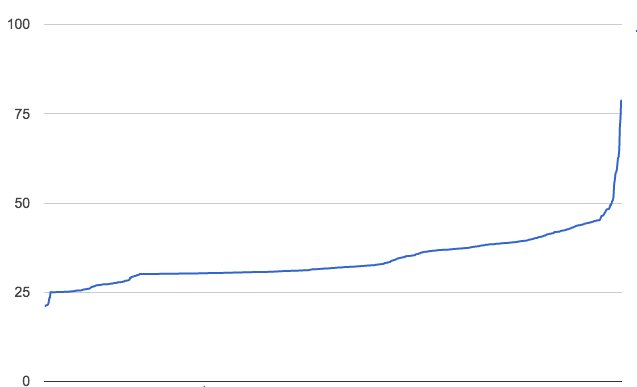
We notably sort works by iconicity in search results and in the carousel on top of artist pages. We also have made it available in our public API.
Comments